
865,000 Tokens: Building NomFeed with Opus 4.6

TL;DR
I built NomFeed, which handles URL conversion, YouTube ingestion, LLM extraction, MCP server, and Chrome extension, using 865,000 tokens with Opus 4.6. The 20x efficiency gain came from architectural discipline: separating human reasoning from model generation, with every specification decision made before the prompt was sent.
I burned through 6 billion tokens last month.
A single orchestrated prompt session consumed 20 million. I was operating at a scale I had never measured, let alone optimized. The environmental cost was real and growing, and I had treated it as external to my responsibility.
I set a constraint: build production software with genuine architectural discipline around token economics. Not less AI. Better AI.
I built NomFeed, which handles URL conversion, YouTube ingestion, LLM extraction, MCP server, and Chrome extension, in 865K tokens with Opus 4.6. 0.014% of baseline consumption.
865,000 tokens. 5.5 hours of active work. 1,850 lines of production code.
The Architectural Decision: Separate Reasoning from Generation
The efficiency gain came from one architectural decision: I owned the specification, Opus owned synthesis.
Large language models predict tokens that resemble reasoning. This is useful for exploration, when you don’t know the answer and need the model to fill gaps. It is expensive, slow, and wasteful when you already know what you want.
These models excel at code synthesis at scale. Humans cannot compete here. Given a complete specification, Opus 4.6 generates hundreds of lines of correct, working code in seconds.
I stopped conflating exploration with implementation. For NomFeed, I did the thinking myself: constraints, interfaces, failure modes, the full decision tree. Every architectural choice was made before the prompt was sent. Then I let Opus do what it does well: produce the artifact.
The 20x efficiency gain came from this division of labor, not from using less AI.
The Architecture Decisions
The constraint of minimal token overhead shaped every decision. Every choice served the requirement that each token deliver value.
Flat Files Over Database
Database access requires schema knowledge, SQL generation, migration handling, ORM context. Hundreds of tokens per interaction to establish baseline understanding.
Flat files require none of this:
readFileSync(): established APIJSON.parse(): established API
The storage layer (store.ts) is 200 lines. No dependencies. No migrations. When I needed extraction storage, the specification was minimal: “save a second file with .extraction.md suffix.” No ORM ceremony, no token overhead.
The 3-Strategy Cascade
URL conversion tries three strategies in order. Cloudflare first (fastest, returns text/markdown). Jina Reader second (handles JavaScript SPAs). Readability plus Turndown last (universal fallback). Each strategy is ~25 lines. First success wins. No agent coordination. No fallback discovery. The cascade is explicit because I specified it completely before implementation began.
Dumb Pipes Over Agents
LLM extraction runs 6 patterns in parallel via Promise.all. Each pattern is a single API call with a focused system prompt. No agent loop, no tool use, no state management, no chain-of-thought. The extraction layer is 70 lines.
The phrase “dumb pipe” encodes the architectural constraint: single input, single output, no side effects. This rules out agents, tool use, and the thousands of tokens per extraction that orchestration requires.
Clear architectural constraints in the initial prompt prevent iterative waste. The specification is complete before the prompt is sent; the model only implements.
What I Built
NomFeed is a local-first CLI tool:
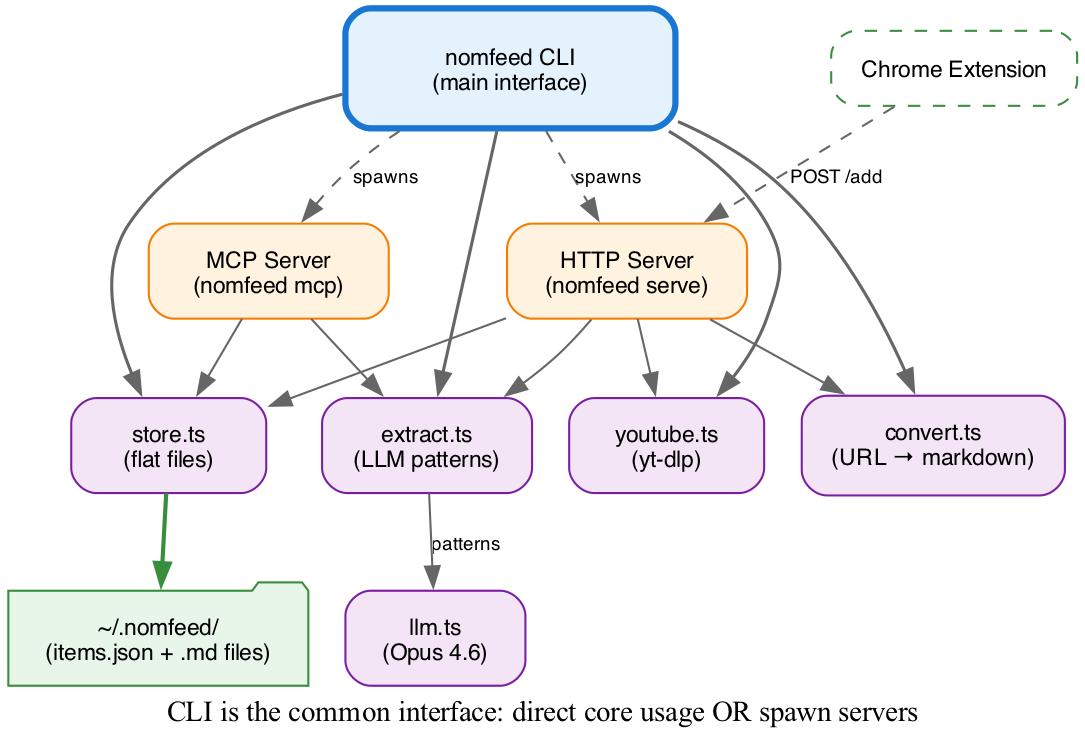
Core capabilities:
- URL conversion via 3-strategy cascade (Cloudflare → Jina Reader → Readability)
- YouTube ingestion via yt-dlp (no API key, full transcripts)
- LLM extraction with 6 Fabric-inspired patterns running in parallel
- Flat-file storage: JSON index + markdown files
- MCP server for agent integration
- Chrome extension via HTTP API
Nine source files. Five dependencies. No build step.
The Environmental Reality
865,000 tokens is roughly 260–865 watt-hours. 13–43 laptop charges. 0.5–2 miles of driving.
At 6 billion tokens per month, the environmental impact of architectural approach choice is substantial. A single 20-million-token sub-agent session consumes more electricity than this entire project.
The difference is not cost. It is the difference between intentional, directed computation and exploratory, continuous burn. Both have their place. Knowing which to use when is the skill.
I used to run sub-agent swarms without considering the token cost. The agents felt like free labor. At 6 billion tokens a month, they are not. Recognizing that changed how I architect systems.
The Prompts
Each prompt contains the complete specification. No agent discovers requirements, explores alternatives, or coordinates with peers.
Prompt 1: Storage Layer
“Flat-file storage: ~/.nomfeed/items.json for the index, ~/.nomfeed/content/{id}.md for markdown files. Each .md file should have YAML frontmatter with source, title, savedAt. Use nanoid for IDs. No database, no ORM.”
Result: 200 lines, zero dependencies, zero iteration.
Prompt 2: URL Conversion
“Three-strategy cascade for URL → markdown:
- Try Cloudflare: fetch with Accept: text/markdown, check Content-Type header
- Try Jina Reader: https://r.jina.ai/\{url\}, 30s timeout
- Fallback to Readability: fetch HTML, parse with @mozilla/readability, convert with turndown Each strategy returns {title, markdown} or null. First success wins.”
Result: 80 lines, handles 95%+ of URLs, no iteration.
Prompt 3: LLM Extraction
“Dumb pipe extraction: each pattern is a system prompt that takes content and returns markdown. Run patterns in parallel with Promise.all. Patterns: extract_wisdom, video_chapters, analyze_claims, extract_references, summarize, rate_content. Save results to {id}.extraction.md.”
Result: 70 lines, 6 patterns, parallel execution.
Prompt 4: YouTube Ingestion
“YouTube via yt-dlp: —dump-json for metadata, —write-subs —write-auto-subs for VTT. Parse VTT to deduplicate overlapping cues. No API key needed. Return {title, channel, duration, transcript, transcriptPlain, markdown}.”
Result: 150 lines, no API credentials, works on any video with subtitles.
Note the specificity: exact yt-dlp flags, exact return structure, explicit constraints. This eliminates the exploration phase.
When Sub-Agents Still Make Sense
I did not eliminate sub-agents entirely. I used one for the skill file:
“I want to create a skill for NomFeed… Please generate the complete SKILL.md content following pi’s skill format with proper frontmatter…”
Appropriate because:
- The output format (pi skill structure) was external knowledge I did not want to load into context
- Single, self-contained document
- No coordination with other components
- Task was “generate content to spec” not “explore and implement”
Sub-agents excel at:
- Exploration when you do not know the solution space
- Research across large codebases or documentation
- Content generation following external formats
- Tasks that can fail independently without blocking progress
Direct prompting excels at:
- Implementation when you know exactly what you want
- Tight integration between components
- Rapid iteration on architectural decisions
- Constraints you want to enforce across the entire system
What I Learned
1. Own the Specification
Thinking models fill gaps with their own reasoning. This is powerful when you do not know the answer. It is waste when you do. By using Opus 4.6 with explicit constraints instead of extended thinking, I replaced model exploration with clear direction. The 20x token difference comes from who owns the specification.
2. Direct Prompting Burns No Idle Tokens
Sub-agent swarms run for hours. A 20-million-token session spans 4-6 hours of continuous computation. Direct prompting only consumes tokens when you hit enter. The gaps between prompts, where you review, decide, and live, are genuinely free.
3. Constraints Are Features
Flat files do not scale to millions of items. Our search is brute-force. These limitations saved thousands of tokens in complexity. Building for actual needs, not hypothetical scale, is an efficiency choice.
4. The Real Partnership
This is not about using less AI. It is about using AI for what it is genuinely good at. Humans provide judgment, direction, constraints. Models provide code at scale. Both operate at peak capability. That is the partnership.
The Activation Loop
NomFeed is a practical tool:
nomfeed add https://youtube.com/watch?v=xyz --extractnomfeed read abc123 --extractThe environmental cost of that extraction (~2,000–4,000 tokens) is negligible compared to the value of structured, searchable, agent-accessible knowledge.
The Numbers
| Metric | Value |
|---|---|
| Total tokens | ~865,000 |
| Active work time | 5 hours 26 minutes |
| Tool calls | 606 |
| Files created/modified | 41 |
| Lines of production code | ~1,850 |
| Sub-agent calls | 1 (for the skill file only) |
| Monthly token consumption | ~6,000,000,000 |
| This project as % of monthly | 0.014% |
5.5 hours of focused work. No multi-hour agent runs. No coordination overhead. No tokens burned while I slept.
Try It
git clone https://github.com/ameno-/nomfeedcd nomfeedbun installbun link
# Save your first URLnomfeed add https://example.com/article
# Search your librarynomfeed search "transformers"GitHub → | Architecture docs →
865,000 tokens. 5.5 hours of active work. 1,850 lines of code. I am still a heavy consumer of AI. But I no longer treat the underlying constraint as someone else’s problem.
Key Takeaways
- 865,000 tokens vs 20M for comparable sub-agent workflows; the efficiency gain comes from who owns the specification
- Opus 4.6 excels at code synthesis, not reasoning; optimal division is human judgment directing machine output
- Flat files, 3-strategy cascades, and dumb pipes emerged from the constraint that every token must deliver value
- At 6B tokens/month scale, architectural approach choice has substantial environmental impact
- Direct prompting burns no idle tokens; sub-agent swarms run continuously for hours